Can World Models Achieve Mapless Path Planning with Semantic Targets?
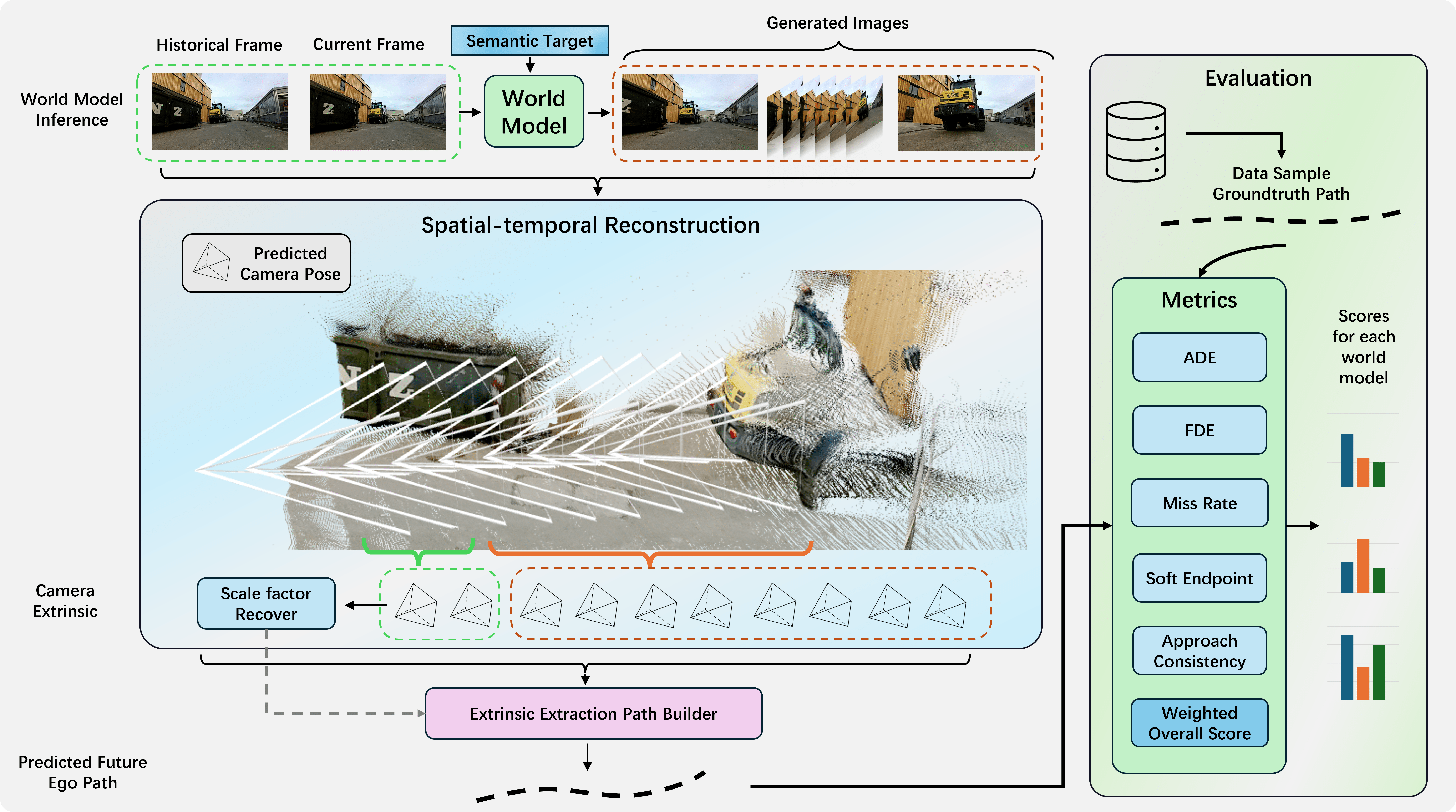
Target-Bench Framework. The pipeline comprises three stages: 1) World Model Inference generates video predictions conditioned on a semantic target; 2) Spatial-temporal Reconstruction recovers camera poses from generated frames; 3) Evaluation compares the reconstructed path against ground truth.
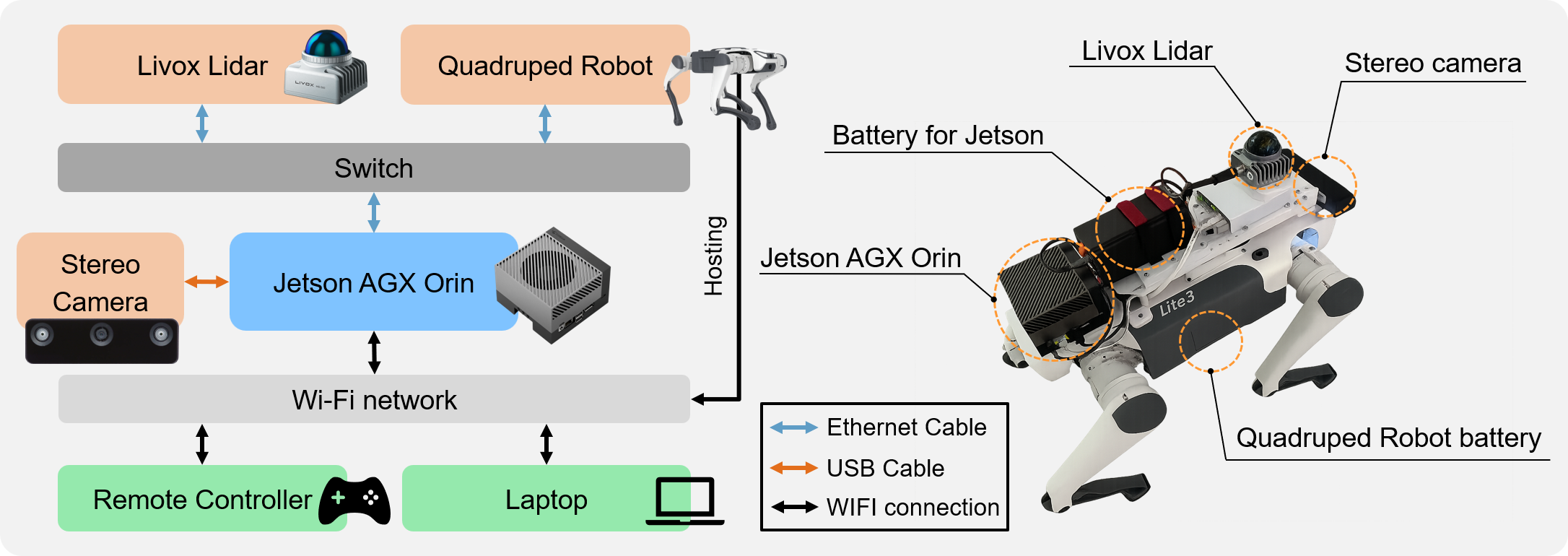
Hardware Configuration. The data collection platform is a Unitree Go1 quadruped robot. Key sensors include a Livox MID-360 LiDAR for mapping and a Realsense D435i stereo camera for visual data. A Jetson AGX Orin handles onboard processing, with a switch managing connections between components.
Compare ground truth robot navigation videos with different video generation models.

Task: Move next to the person and stop at the side of the sofa
Current Frame
Ground Truth Video

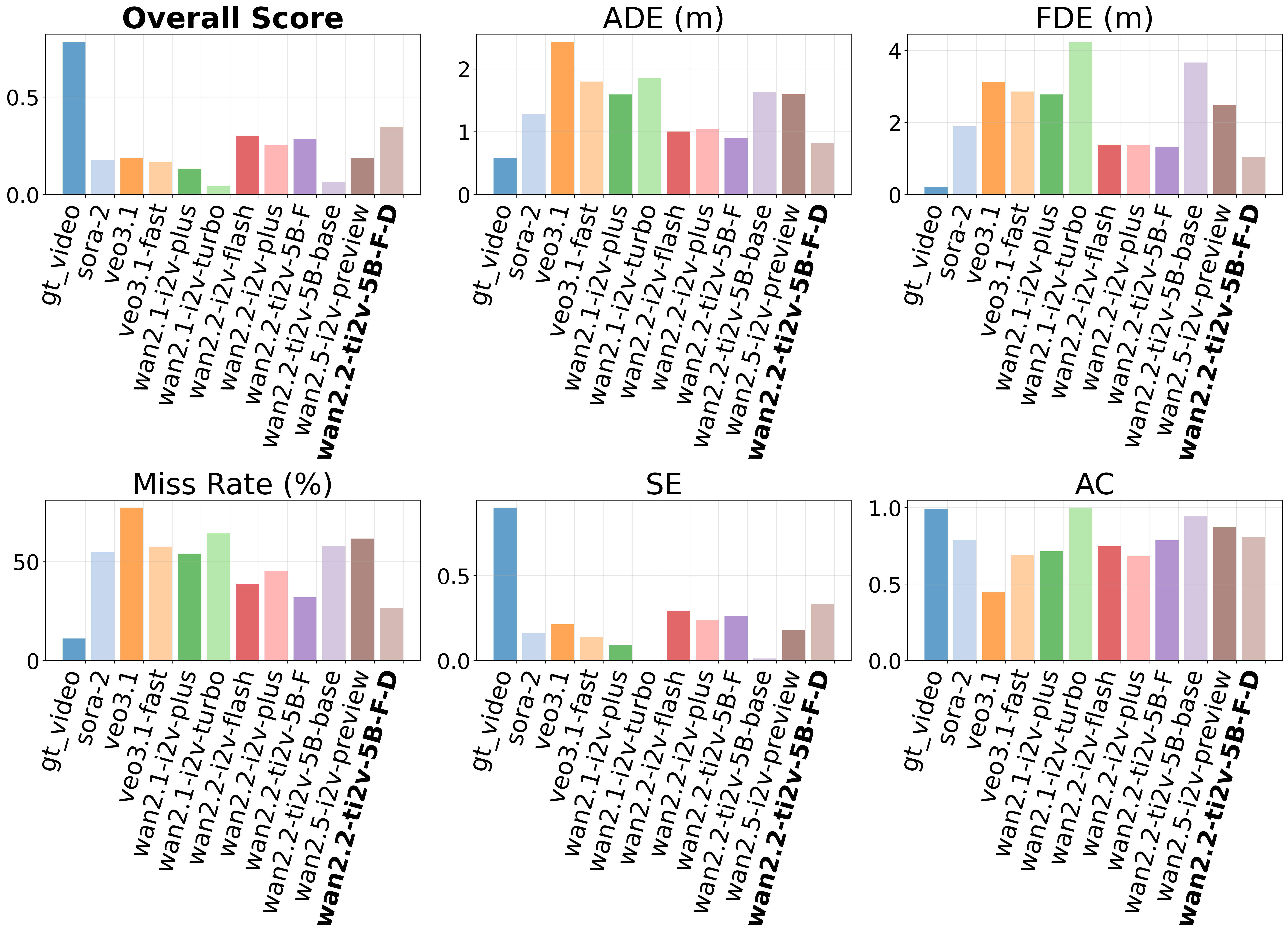
World Models Comparison. We benchmark state-of-the-art video generation models (Sora, Veo, Wan series). To evaluate their planning capability, we introduce a Weighted Overall (WO) Score to quantify performance, aggregating five key metrics: Average/Final Displacement Error (ADE/FDE) for accuracy, Miss Rate (MR) for reliability, and Soft Endpoint (SE) with Approach Consistency (AC) for semantic goal adherence.
World model performance comparison with VGGT as world decoder’s spatio-temporal reconstruction tool.
World Decoders Comparison. We employ VGGT, SpaTracker, and ViPE as world decoders to recover 3D camera trajectories from the generated videos, enabling direct comparison with ground truth paths.
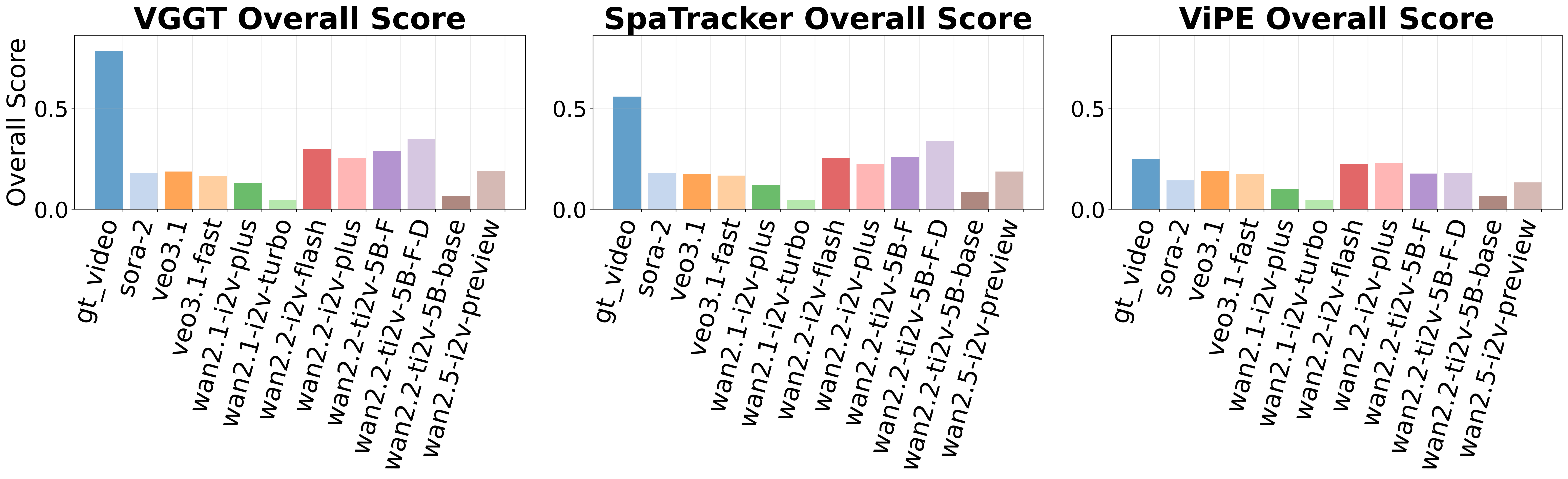
Overall score comparison between different spatio-temporal reconstruction tools.